HPA Algorithm
For those who have experimented with Kubernetes or any of its variations, configuring HPA (Horizontal Pod Autoscaler) has likely been attempted at least once to address concerns about resource overconsumption during high application loads.
At this point, it is assumed that most of us know how to configure HPA for a specific application. However, working with multiple customers has revealed lingering confusion regarding how HPA calculates resource consumption and determines scaling actions.
While the Kubernetes documentation provides precise information on these matters, it often requires referencing multiple documents to grasp all aspects of HPA. To save you the hassle of searching through relevant documentation, I will consolidate everything I've learned about HPA in one place.
Request-Based Scaling:
In the current configuration, HPA targetCPUUtilization and targetMemoryUtilization are based on requests.cpu and requests.memory, respectively. You can find a detailed example here.
There have been ongoing discussions within the community about configuring HPA algorithm to be based on limits instead of requests. However, a specific issue remains unresolved as there is a conflict regarding the most efficient approach (limits or requests).
Target Percentage Within the Range of 100?
When we discuss setting a percentage of utilization based on standard terms, it is usually assumed that the target should be less than or equal to 100%. However, in the case of HPA, this is not necessary. I, too, was initially confused about the "why" and "how" of this aspect, but by delving into various discussions and judgments, I gained clarity.
Currently, HPA uses resources.requests as the foundation for calculating and comparing resource utilization. Thus, setting a target above 100% should not pose any issues as long as the threshold (targetUtilization) is less than or equal to resources.limits.
For example, let's deploy an application with resources.requests.cpu=200m and resources.limits.cpu="4" for each container. Configure an HPA with targetCPUUtilization=300% for this application. Now, whenever the average consumption of all application pods reaches 300% of 200m (requests.cpu), i.e., 600m, new pods will scale up.
How Many Pods Will Scale Up?
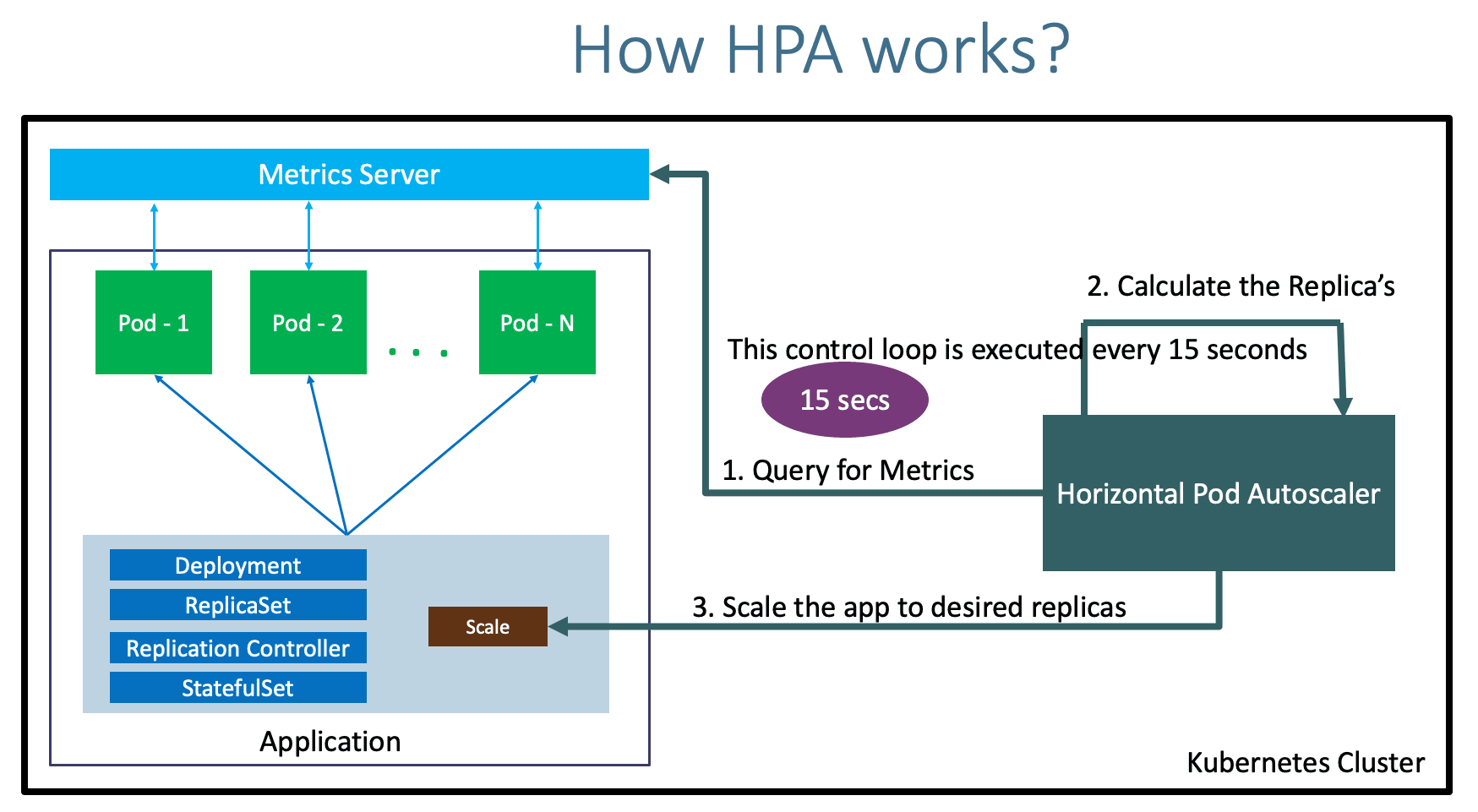
Kubernetes follows a simple algorithm to calculate the number of pods that need to be scaled up or down, as described here:
desiredReplicas = ceil[currentReplicas * (currentMetricValue / desiredMetricValue)]
What's the Waiting Period?
When designing HPA, the goal of avoiding constant fluctuations in the number of pods due to traffic/load is crucial. To achieve this, a default stabilization window of 5 minutes is implemented.
HPA monitors the application load, and if the current utilization remains below the target for 5 minutes, it begins scaling down the pods. However, if the load increases above the target within the stabilization window, the pods will wait for another 5 minutes before scaling down.